-
[3D Reconstruction] 얼렁뚱땅 Occupancy Networks: Learning 3D Reconstruction in Function Space 논문 리뷰얼렁뚱땅 논문리뷰 2022. 2. 1. 22:15
3D reconstruction에서 반드시 읽어보아야 하는 논문이라고 생각이 드는 논문 !

사실 이번이 3번째 읽은 것이고,
그렇다고 쭈루룩 3번 읽은 것이 아니라 은근 텀 있게 3번을 읽어서
읽을 때마다 너무 새로웠던 .. ㅎㅎ
안 새롭고 .. 바로 이해가 갈 수는 없는걸까 ? ㅎ_ㅎ.........
또 잊어먹으면 4번째 읽으면 되는거지 모 !
...ㅎㅎㅎ................아니 그러면 되는거지 뭐 !!!!!
Introduction & Related Work
3D reconstruction 분야는 말 그래도 3차원 재구성이다.
2차원 이미지를 가지고 3차원을 재구성 하거나, 혹은 어떠한 3차원 데이터를 input으로 3차원 재구성을 하거나..
2차원 이미지를 이용한 것들은 많은 발전이 있던거에 비해, 3차원 재구성은 활발히 연구가 되고 있는 분야기는 하나 아직 그렇게 크게 발전이 되지는 않았다.
3차원 재구성을 하기 위한 Output의 Format 즉, 3D representation은 크게 아래 a, b, c 처럼 3가지로 나뉘었다
Voxel 데이터는 일정한 grid를 가지고 하는 것이다.
그러다 보니 3D CNN 아키텍처를 활용할 수 있다.
하지만, 일정한 grid를 가지다 보니 굳이 재구성에 필요없는 부분도 깊게 보게 되고 그러다 보니 메모리에 한계가 있다.
최근 아키텍처의 발전으로 256^3까지 발전은 하였으나, 사실 그 전에난 32^3, 64^3..
실질적으로 이용하기에는 너무 작은 grid였다.
256^3도 사실 엄청 좋은 grid라고 하기에는 어느정도 한계가 존재한다.
Pointcloud는 이름에서 보이듯이 마치 점 구름이다
Pointcloud의 단점은 연결성이 없이 점만 있다는 것이다
그래서 연결성이 있는 Mesh 데이터로 만들어 주기 위해서는 후처리 과정이 추가적으로 필요하다
하지만, voxel의 복잡성은 조금 해결 할 수 있었다
Mesh 표현은 점과 선으로 연결되어 있는 데이터라고 생각하면 편하다
Mesh 데이터에서 있는 점들만 뽑으면 Pointcloud라 할 수 있다
Mesh는 Pointcloud가 가지고 있지 않는 연결성을 알 수 있다.
즉, '이 점과 이 점은 연결되어 있구나 ! 오호 ! 그럼 가까운 관계네 (?).... ㅜ' 무튼 뭐. .이런식
하지만 Mesh데이터를 3D representation으로 사용한 논문의 경우, 정말 간단한 모양의 Template 모델을 이용해서 input 데이터에 맞게 변형(?)해 준다.
그러다 보니 엄청 정교한 것들은 잘 표현하지 못하는 경향이 존재한다.
그리고 또 다른 한계는 닫힌 표면에 대해 확신을 하지 못한다. 즉 매끄러운 쭉 표면이 아니라 겹겹히 되어있는 형태의 표면이라던가.. 이런 것이 발생 할 수 있다.
Pointcloud와 Mesh의 또 다른 문제는
'몇개의 점, 몇개의 선을 사용한 것을 정교하다고 생각할거야 ? ' 라고 질문 한다면 음 .. . 엄 .. ㅎㅎ
이렇게 된다는 것 또한 문제이다

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 그래서 본 논문의 Contribution은
1. 새로운 3D geometry representation을 소개해준다 !
(해당 점이 3D 물체 안에 있는 걸까 밖에 있는 걸까를 0~1 범위의 연속적인 값으로 표현한다)
2. 다양한 input 데이터를 이용해서 3D representation이 가능하도록 해준다
(Point cloud, voxel, 2D image)
3. 아주 좋은 퀄리티의 Mesh 형태를 할 수 있으며, SOTA를 달성했다
(기존 저차원만 가능했던 다른 표현들과 달리 아주 효율성이 좋기 때문에 좋은 퀄리티가 됨)
Method
Occupancy Networks
아래 사진이 Occupancy Networks를 가장 잘 설명한 것이라고 할 수 있다.
진짜 쉽게 생각하면, 어떤 한 점이 3차원 물체 안에 있는거 같아? 그럼 ! 1, 아니면 0에 가깝도록 학습해!
뭐.. 이런 느낌. ... ?

출처 : https://autonomousvision.github.io/occupancy-networks/ Occupancy Network는 고정되어있는 Fixed 3D 좌표 뿐만아니라, 그 안의 모든 좌표들도 추론이 가능하다
가능한 많은 3차원 좌표들의 Occupancy Probability(점유 확률, 즉 물체 안에 있을 거 같아?)을 0부터 1까지 표현하고자 한다.
즉, 마치 binary classification처럼 특정 Boundary(threshold) 이상이면 Occupancy되었다(물체 안에 있다), 아니면 여기는 물체 밖이다라고 생각하면 쉽다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 여기서 X는 Input 데이터의 표현이라고 생각하면 쉽다
즉 input 데이터의 어떤 표현과 3차원 좌표를 기반으로 이 3차원 좌표의 점유 확률을 표현한다
따라서, 함수 F는 input으로 3차원 좌표와 3차원 좌표를 받고, 그것에 대한 점유 확률을 output으로 생성하는 함수다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 다른 Pointcloud, voxel, mesh 등은 눈에 보이는 output을 생성한다고 한다 즉 직관적이다
예를들어, Voxel의 output형태는 3차원 그리드 안에 색칠되어 있는 듯한 Output이다
하지만 Implicit 는 다르다
Output만 보면 0과 1 밖에 없는 형태인거다
.. 정말 뭔지 모르겠지 않는가 .. 그래서 암시적이라고 한다.
3차원 좌표를 보았을 때, 아 이 점에 대해서 점유를 말하는구나 라고 알 수 있지만, Output만 보면 뭐인지 모른다
하지만, 이렇게 함으로써 굉장히 효율성을 높였다고 한다.
정말 이해가 잘 안될 거 같아서 논문에 없지만 유튜브에 있는 아키텍처를 가져왔다.
Input의 형태가 2D 이미지, Pointcloud, Voxel이 될 수 있고 그에 맞는 Encoder이 따로 존재한다.
스포 하자면 2D 이미지는 Imagenet으로 Pretrained된 Resnet18이다.
무튼 그래서 Input 데이터를 Encoding하여 특정 차원의 벡터 c로 표현한다.
그러고 밑에 병렬적으로 있는 3D Location과 c(input 정보)를 이용해서 Output Occupancy prob를 도출한다
만약 3d location이 R^3차원이라면(3은 x,y,z) Occupancy prob는 R 차원이다 왜냐면 하나의 점에 대해 하나의 Prob를 도출하니까 !
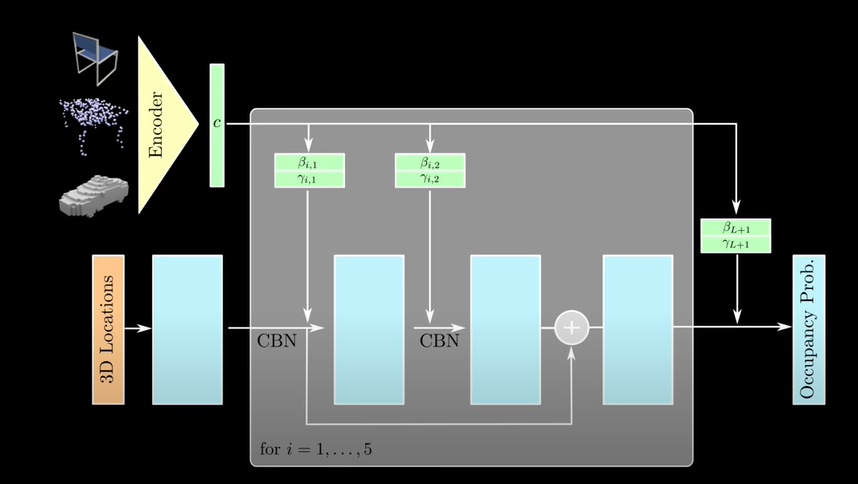
https://www.youtube.com/watch?v=w1Qo3bOiPaE Training
함수 F는 Neural network 형태이다.
F의 파라미터들을 학습시키기 위해 어떻게 하면 좋을까.. 에 대한 것이다
Loss Function을 보면, 어디서 좀 본 친구다 !
Cross entropy classification loss이다 !
F 함수에서 도출한 Occupancy Prob와 실제 Occupancy 했는지(맞으면 1 아니면 0)의 Cross entropy를 본 것이다 !
여기서 Mini batch 형태를 채택했다. B는 Batch 다

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 음 .. 그러니까 여기서 보는 것은 얼마나 잘 Generate 시켰냐에 대한 Loss를 보는 것이다.
encoder network를 이용해서 해당 점과 해당 점의 Occupancy(2차원 상에서의 Occupancy)를 Input으로 가우시안 분포에 맞게 평균과 분산을 추론한다.
(사실 무슨 말인지 잘 모르겠다 ㅎ)

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Inference
물체의 표면을 추출하기 위해서 본 논문에서는 MISE(Multiresolution Isosurface Extraction)를 제안하였다
Occupancy Network는 앞에서 말했다시피 Output 값이 Occupancy 값이다보니, 점에 대한 Occupancy만 보는 것이다
즉 Mesh형태의 연결관계를 알기 위해서는 추가적인 단계가 필요하다.
Voxel 등은 정해져있는 resolution에 대해서 3D reconstruction을 수행한다
하지만, Occupancy Network는 가능한 많은 3D 점에 대해 Occupancy를 추정하고자 한다고 하였다.
그것이 어떻게 되는 것인지 이제 설명 할 수 있다.
1. 최초에는 정해져있는 Grid가 존재한다. 저자는 32^3을 초기의 Grid로 설정하는 것만으로 충분하다고 한다
2. 초기 Grid에 대해 모두 Occupancy Prob를 확인한다
3. Occupancy Prob를 보았을 때, Threshold를 넘는 값들을 따로 Mark 한다(Active 한다)
4. 한개의 voxel(한 칸)에서 Occupancy와 Occupancy가 아닌것이 모두 있는 것을 찾고 그 Voxel을 8개의 subvoxel로 나눈다.
5. 3번과 4번을 원하는 출력 해상도에 도달할 때까지 계속 반복한다
6. Marching cube Algorithm(점만 있을 때 연결관계를 추출하기 위한 알고리즘)을 이용하여 Initial mesh를 추출한다.
7. Fast Quadric Mesh Simplification algorithm을 이용하여 메시를 simplify하고
8. 1차 및 2차 Gradient를 이용하여, 출력 메시를 개선한다.
따라서, 아래 사진에서 볼 수 있듯이, 최초의 Grid 내에서만 추정하는 것이 아닌 세분화되어 Multiresolution으로 추정이 가능하다.
모든 Point를 이러한 Resolution으로 보는 것은 굉장히 비효율적이다.
이를 개선하고 인접한 두개가 다른 활성상태인 것을 8개의 subvoxel로 나누면서, 기존의 방법론들에 비해, 굉장한 에너지 절약이 가능하다고 할 수 있다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 위의 단계를 잘 수행하기 위해 Loss Function을 추가적으로 이용한다.
pk는 Output Mesh에서의 표면에서 임의로 Sampling 한 점을 의미한다.
앞의 식은 쉽게 생각하면, 표면에서 샘플링한 점의 Occupancy를 보는 것이기 때문에, 표면에 존재하는 점을 Threshold(안과 밖의 경계를 결정해주는 값)과 가깝게 예측하기 위한 식이라고 볼 수 있다.
뒤에 식은 2차 Gradient를 최소화 하기 위한 식이다. n(pk)는 pk점의 법선 벡터를 의미한다
무튼 이러한 식으로 인해 Double Backprogation으로 더 효율적으로 가능하다고 한다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Implementation Details
Occupancy Network는 Fully Connected neural network로 구성되었으며 총 5개의 residual block을 사용한다
그리고, Input를 Conditional한 값으로 계속 넣어주는데, Conditional batch normalization을 이용한다
input type에 따라, encoder를 다른 것을 사용하는데
2D 이미지의 경우 Resnet 18, Pointcloud의 경우 Pointnet, voxel의 경우 3D CNN을 이용한다
Experiments
Baseline
Occupancy network과 비교하기 위한 Baseline로써, 3D R2N2(Voxel), PSGN(Pointcloud), Pixel2Mesh(Mesh), AtlasNet(Mesh)를 사용한다.
괄호 안에 들어 있는 것은 Output의 형태를 의미한다.
Dataset
ShapeNet 데이터 셋을 이용한다
Metrics
volumetric IoU와 Chamfer-L1 Distance, Normal consistency score를 이용하여 평가한다
Volumetric IoU는 실제 정답 데이터와 예측 데이터의 교집합 부분을 보는 것이다
즉, 교집합이 크면 클수록 정답과 가깝게 예측했다고 할 수 있다.

Ge, Yuanyue, Ya Xiong, and Pål J. From. "Symmetry-based 3d shape completion for fruit localisation for harvesting robots." Biosystems Engineering 197 (2020): 188-202. 그다음에 Chamfer-L1 Distance는 Accuracy 와 Completeness의 Metric라고 할 수 있다.
Accuracy 측면은, GroundTruth(정답) 메시에서 가장 가까운 이웃에 대한 Output Mesh(Prediction) 점의 평균 거리로 정의 된 것을 의미한다.
Completeness는 100k개의 점을 임의로 추출하고 KD tree를 이용하여 해당 거리를 추정하는 것을 의미한다
여기서 KD Tree는 각 노드의 데이터가 공간의 K차원 포인트인 이진 검색 트리를 의미한다.
마지막 normal consistency는 말그대로 Groundtruth의 normal과 Prediction의 normal이 얼마나 일관성을 가지고 있느냐를 의미한다. 따라서, absolution dot product(절대적 내적(?))을 이용하여 일관성 점수를 정의한다.
Representation Power
여기서는 Chair 즉 의자 데이터를 학습시키고 의자 데이터에 대한 결과값을 기반으로 평가한 것이다
아래 그래프에서 확인 할 수 있듯이, voxelization 된 알고리즘의 경우, 초기 Resolution이 증가하면 증가할수록, IoU성능은 좋아지지만 파라미터의 수가 기하 급수적으로 늘어나는 것을 확인가능하다
그리고 낮은 resolution의 voxel의 경우 그냥 보아도 굉장히 투박한 것을 볼 수 있다.
Onet은 아래 사진을 보았을 때, 효율적인 네트워크라고 볼 수 있다
왜냐하면, 우선 IoU 값이 초기 Resolution에 크게 의존적이지 않으며 성능이 매우 좋다 또한 Parameter의 수도 적다.
Occupancy network의 IoU 값은 0.89로 평균적으로 수렴한다고 한다.


Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Single Image 3D Representation
Input으로 Single Image가 들어왔을 때, 얼마나 잘 예측하나를 보고자 한다
그리고, Shapenet 데이터 이와의 KITTI, Online Products dataset을 이용하여 학습한 Shapenet 데이터 이외의 Realworld 데이터를 사용하였을 때도 잘 예측 되는지를 확인하고자 한다.
3D R2N2의 경우에는 Course한 예측을 하는 것을 확인 가능하다 또한 디테일 측면에서 예측을 잘 하지 못한다
PSGN는 Pointcloud를 Output으로 연결성에 대해서 정보가 부족하다. 따라서 추가적인 단계가 필요하다
Pixel2Mesh는 종종 구멍을 제대로 예측 하지 못한다. 따라서 밑에 그림도 보면 구멍이 뚫려야 되는 부분이 채워져있는 것을 볼 수 있다.
Atlasnet의 경우 geometry한 특징을 잘 예측하지만, 표면이 겹치는(?) 양상이 많이 보인다
매끈하지 않고, Overlapping 되어있는 것처럼 보인다
그에 비해, ONet은 디테일을 적당히 잘 살리면서 표면이 매끄러운 것을 확인 가능하다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). 
Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). PointCloud Completion & Voxel Super-Resolution
Shapenet에서 300개의 점을 이용하여 3D reconstuction을 수행 한 것이다
보이는 것과 같이 Onet의 성능이 가장 좋은 것을 확인 가능하다(왼쪽 사진)
그리고 Voxel의 경우 Voxel을 Input으로 Super Resolution이 가능하다는 것을 보여준 것이다
오른쪽 표와 같이 input 데이터에 비해 3가지 metric 모두 개선 된 것을 확인 가능하다


Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Unconditional Mesh Generation
Input 데이터를 사용한 Reconstuction이 아닌 비지도학습 방법으로 Shapenet 데이터를 이용하여 3D Generation에 초점을 맞춰 실험하였다
이 실험을 하는 이유는, Latent Space가 Generation하기에 최적화 되어있는 아주 잘 특징을 잡는다는 것을 보여주기 위한 것이다
각 범주에 따라 따로따로 학습을 진행하였다
아래 사진을 보면 알 수 있듯이 굉장히 잘 생성하는 것을 볼 수 있다
즉, Latent Space를 아주 잘 구성한다 굿!

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Ablation Study
Effect of sampling strategy
Loss Function에서 평가를 하기 위해 Sampling을 하는데, 어떤 방법이 제일 좋냐 ! 에 대한 것이다
(1) 2048개의 표면에 있는 Uniformly Sampling
(2) 1024개 Mesh 내부에 있는 점 Uniformly Sampling, 1024개의 외부의 점 Uniformly Sampling(Equal sampling)
(3) 1024개 Uniformly sampling 그리고 가우시안 노이즈에 따라 mesh 표면에서 1024개 Sampling(Surface sampling)
그리고 sampling 수를 2048에서 64로도 줄여보기도 했다.
밑에 표를 보면, 음 .. Uniform 2048개가 가장 성능이 좋은 것을 확인 할 수 있다 !

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Effect of architecture
움 아까도 말했다시피 Residual block 5개와 conditional batch normalization을 사용했는데 이게 없으면 어떤가~ 하고 본 것이다
당연히 다 있는게 좋겠지 ㅎㅋㅎㅋ 절대 설명하기 귀찮아서가 아니다.

Mescheder, L., Oechsle, M., Niemeyer, M., Nowozin, S., & Geiger, A. (2019). Occupancy networks: Learning 3d reconstruction in function space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 4460-4470). Conclusion
Occupancy Network(Onet)을 소개했습니다. 새로운 3D geometry representation 이죠
딱 정해져 있는 부분만 보는 것도 아니고 Implicit 되어 있기 때문에 realistic한 high resolution mesh가 가능했습니다.
효율성이 좋구요
절대 귀찮아서 그런거 아니에요 진짜 짧아요
우아ㅜ아오라와ㅗ 끝났다 생각보다 징짜 오래걸리네요 이거
하지만 요즘 맨날 까먹기때문에 꼭 이렇게 정리를 해보겠습니다 그럼 안뇽
'얼렁뚱땅 논문리뷰' 카테고리의 다른 글