[OOD 탐지를 위한 GAN 활용] 얼렁뚱땅 Training Confidence-calibrated Classifier for Detecting Out-of-Distribute Samples 리뷰
넘 올만에 써서 어떻게 시작해야할 지 잘 모르겠긴 한데
다시 한 번 시작해보자구

Introduction
- DNN을 이용하여, Image, Speach 등 다양한 Classification을 성공적으로 해냄
- 이러한 기존 딥러닝 모델들의 한계점은 높은 신뢰도를 부여하는 경향이 존재함
- 높은 신뢰도를 부여한다는 의미는 OOD 데이터에도 ID 데이터 보다는 낮은 값이지만 한 클래스에 높은 Confidence score를 부여한다는 것을 의미함
- Out of Distribution(OOD) : 학습 데이터에서 사용하지 않은 클래스 or 도메인에 포함되는 입력을 탐지하고자 하는 Task 임
- 예를 들어, 고양이와 개를 분류하는 모델을 학습시켰는데 갑자기 고래 사진이 들어올 때 이 고래 사진은 OOD 데이터다 라고 판별하는 것을 목표로 함
- OOD 데이터의 예시는 밑에 빨간 박스임

- 기존 연구들(OOD)에서 가장 많이 사용하는 것은 Threshold를 이용하는 것임(아래 사진 예시)
- 그리고 기존 연구들을 보면 이와 같이 이미지를 특정 Label로 분류하는 모델 즉 이미 학습된 모델(Pretrained Model)을 사용하여 OOD를 수행함
- OOD : g(x) : X -> {0,1} 이라면, Threshold화 confidence score를 비교해서 ID 이면 1 OOD 이면 0으로 분류
- 여기서 말하는 Confidence score 는 Class 예측 분포에서 가장 큰 값을 의미함
- 이는 Classification 모델(ID만을 사용한)에 의존적으로 OOD를 수행하는 것이라고 할 수 있음

- 본 연구의 Contribution
- OOD 탐지를 위해 Confidence Classification 제안
- 이를 수행하기 위한 Confidence Loss 제안
- KL Divergence를 이용해 OOD 데이터의 경우 클래스 분포가 Uniform과 비슷하게 예측하도록 하면서, max Confidence value가 작아지도록 함
- GAN을 이용하여 OOD 데이터를 생성하고 이를 이용하여 Classification 모델을 학습함
Training confident neural classifers
Confident Classifier for out of distribution
- ID, OOD 데이터 모두 학습을 진행함
- 아래 Classifer를 위해 사용하는 Loss임(Confidence Loss)
- 왼쪽은 일반적으로 Clssifacation을 수행하기 위한 Cross Entropy 임
- in data 이미지 x가 들어왔을 때 y라고 잘 예측할 수 있도록 하는 Loss임
- 오른쪽은 KL Divergence로 Uniform 함수와 예측 클래스 분포가 비슷해지도록 하는 Loss임
- OOD 데이터가 들어왔을 때 클래스 분포가 Uniform하게 예측하도록 KL Divergence를 이용함
- 기존 Classification Loss에서 오른쪽을 추가 하였지만, Classification의 성능저하는 크게 오지 않음

- 그런데 본 연구자들이 실험을 통해 알아낸 사실이 있는데, 그게 뭐냐면 OOD 데이터가 너무 이렇게 저렇게 생긴거 보다는 ID에 가깝게 OOD 데이터가 생겼을 때 더 Class 예측을 잘한다는 것을 알아냄
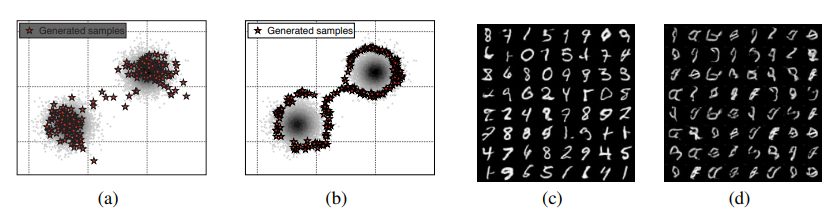
- 2D 데이터를 이용해서 실험한 예시는 아래와 같음
- (a)를 보면, out 데이터가 in 데이터들과 멀리 떨어져 있는데, 이 out 데이터로 Confidence loss를 이용해 학습하면, (b)와 같이 실제 데이터 분포보다 Confidence하다고 예측하는 부분이 넓어짐
- (c)가 비교적 (a)에 비해 in 데이터와 가깝게 out 데이터들이 있다고 볼 수 있는데, 결과인 (d)를 보면, 실제 데이터 쪽은 각각 class 0과 1로 잘 예측하고 그 외의 OOD들을 제대로 탐지하는 것을 볼 수 있음

- 따라서, 본 연구에서 OOD 데이터가 ID에 가까울수록 더 실제 Class 예측을 잘한다(더 분리되어 있다)라고 볼 수 있음
- 그래서 본 연구에서는 GAN을 이용해서 ID 데이터와 유사하지만 다른 데이터(out 데이터)를 생성해서 더 잘 분리하고자 함
Adversarial Generator For Out-of-Distribution
- GAN을 이용한 이미지 생성이 필요한 이유 중에 하나는 실제 해당 Classifier을 명시적인 데이터를 이용하여 학습을 진행할 수 있지만, 실제 어느 데이터를 Out 데이터로 사용해야 하는가 ? 데이터 자원은 항상 충분한가 ? 등의 의문점을 남길 수 있기도 하고, 위의 실험결과에서 in 데이터와 유사한 데이터를 out으로 사용할 때 성능이 더 잘나오는 것을 보고 GAN을 이용하고자 하는 것임
- 본 연구에서는 기존의 GAN을 활용하여, OOD 탐지를 더 잘 할 수 있도록 이미지를 생성하는 GAN을 제안함
- 아래는 OOD 탐지를 위해 제안하는 GAN의 Loss임
- In Distribution의 데이터를 생성하는 것이 아니라, ID와 유사한 Out Distribution 데이터를 만들고자 함
- a) 는 GAN이 생성한 이미지가 분류모델에 들어갔을 때 Uniform한 클래스 분포를 따르도록 해서 ID 분포에서 벗어난 OOD 데이터를 생성하고자 하는 것임
- b) 는 그래도 ID와 비슷하게 생성해야 하기 때문에 기존의 GAN Loss도 사용함

Joint Training method of confidence classifier and adversarial generator
- 실제 Classifer과 GAN을 모두 이용할 때의 최종 Loss는 아래와 같음(Joint Confidence Loss)
- (c)와 (d)는 Classifer를 위해 사용하는 Loss 이고 (d)와 (e)는 GAN을 위해 사용하는 Loss임
- 여기서 베타는 하이퍼 파라미터적 성격을 가짐
- 세타가 의미하는 것은 Classfier의 파라미터를 의미함

- alternation으로 학습을 진행함(Discriminator -> Generator -> Classifer)

Experimental Result
- 먼저 Confidence Loss의 효과를 증명하기 위하여, GAN을 사용하지 않고 명시적으로 다른 데이터셋을 OOD 데이터라고 사용하여 실험을 진행함
- 아래 SVHN 데이터를 In 데이터로, Out 데이터를 CIFAR-10으로 실험한 것임
- 기존의 Cross Entropy만을 사용할 때에는 (a) 그림을 보면 대체적으로 ID 데이터인 SVHN에서 눈에 띄게 높은 확률을 주로 예측하지만, 종종 Out 데이터들을 이용해서 0.95 이상도 나오기도 하는 것을 알 수 있음
- (b)와 같이 Confidence Loss를 사용할 때에는 ID일 때 높은 확률 보이고 다른 것들(ood)은 0.15쪽에 완전 예측하는 것을 보여줌으로써 전보다 잘 분류한다고 할 수 있음

- ID가 SVHN이고 CIFAR-10은 ODD로 탐지할 수 있도록 학습을 진행시킬 때, CIFAR-10과 비슷한 성질인 Tiny ImageNet, LSUN 등 다른 비슷해 보이는 데이터 셋이 들어왔을 때도 OOD라고 제대로 판별을 잘 함(성능이 증가함)
- 근데, In을 CIFAR을 사용하고 OUT을 SVHN을 했을 때에는 다른 데이터 셋이 SVHN과 생긴 게 좀 달라서 그런지 판별 성능이 많이 증가하지 않음

- GAN 생성 결과를 비교해보면
- 본 연구에서는 실제 데이터와 엄청 비슷하지만 OUT 데이터를 만드는 것이 목표임
- Joint Confidence loss를 사용할 때, 그 생성 데이터들의 분포는 (b)와 같이 실제 데이터의 분포 근처에 있으나 실제 데이터 분포를 따르지는 않고, (d)와 같이 비슷한 듯 이상한 데이터를 생성함
- 그냥 GAN을 사용하면 (a)와 같이 실제 데이터 분포와 유사한 데이터를 생성함(c)
- 아래 그래프 해석
- in이 svhn인 것을 보면 out 데이터를 cifar로 했을 때 가장 성능이 좋음 이는 cifar과 다른 out 데이터 사이의 유사함 정도가 커서 그러는 것임
- 사실 in과 out 사이의 유사함 정도가 많지는 않은 데이터 셋임(in과 out이)
- 그런데 아래 결과(b)를 보면, Joint Confidence를 이용하여 GAN까지 함께 이용하였을 때, IN과 비슷한데 다른 데이터를 생성해서 더 성능이 개선된 것을 볼 수 있음
- 아래 in을 cifar로 사용하였을 때는 out 학습을 명시적으로 svhn으로 사용할 때에는 다른 out 데이터와 학습한 out 데이터 사이에 유사도가 적기 때문에 큰 성능향상을 이끌지 않음

- 아래는 각 픽셀의 중요도를 보기 위해 Gradient map을 이용하는 것임
- 아래 그림에서 검은색 영역은 low gradietns고 하얀색 영역은 high gradients임
- Gradient가 높게 나온다는 것은 중요한 부분이라고 탐지하는 것이고 이는 높은 확률 클래스를 도출 할 수 있다는 것임
- 하지만 우리가 원하는 것은 ID 에서만 높은 확률 클래스를 도출했으면 좋은 거기 때문에 Out 데이터들에 대해서는 검은색으로 많이 나오는 것이 좋음
- (b)를 보았을 때, joint confidence loss를 사용하였을 때, 보다 Gradient가 낮게 생성되는 것을 볼 수 있음
