[View Synthesis] 얼렁뚱땅 NeFR : Representing Scenes as Neural Radiance Fields for View Synthesis 리뷰

Introduction
- view synthesis : 여러 시점에서 찍은 사진을 이용하여, 새로운 시점에서 보았을 때의 모습을 예측(합성)하는 것이 목표
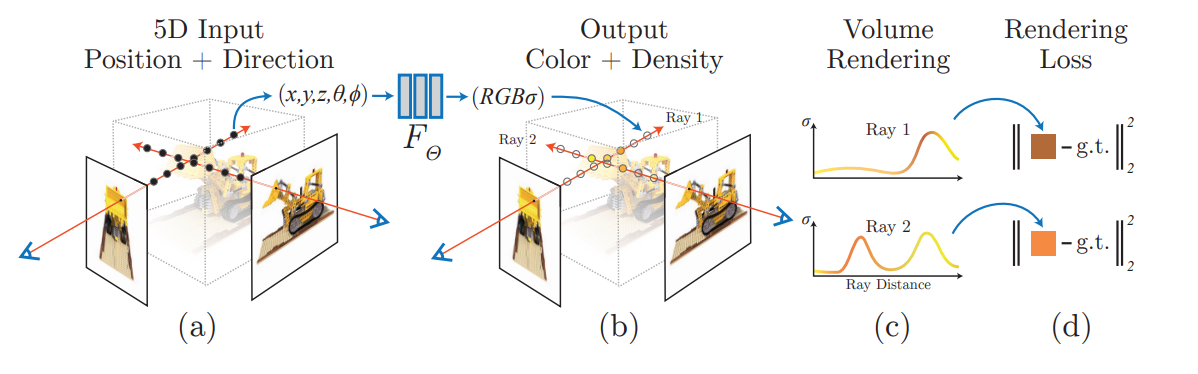
- 본 논문에서는 정적인 장면의 RGB, Density를 Output으로 출력하는 5D 함수를 정의함
- 여기서 5D는 공간의 위치정보 3차원(x,y,z), View Direction 2차원(θ,ϕ)을 의미함
- 즉, Input : x,y,z,θ,ϕ / Output : R,G,B,Density
- Density는 밀도로 투명도와 역의 개념으로 생각하면 됨
- 본 논문에서는 이 5D Function을 MLP(Deep fully-connected neural network)로 정의하였음
- 기존 방법들은 아래 방법과 같이 주로 CNN을 이용함
- Voxel grid에서 RGB값을 추정하고자 하였음
- 하지만 이는 Memory efficienty가 좋지 않다라는 한계가 있으며, 고해상도 확장성에 한계를 가지고 있음

- 본 논문의 접근 방식을 정리하면 다음과 같음
1. Static Scene을 통해, 카메라의 광선(rays)를 진행시켜서, 임의의 3D Points set을 생성함
2. 그러고, 이러한 점들과 2D Viewing Direction을 Network의 입력으로 사용하여, 각 점들의 Color와 Density를 예측함
3. classical한 volume rendering을 사용하여, 이러한 Color와 Density를 이용해 2D에서의 Color와 Density를 예측함
- 이러한 과정들은 자연스럽게 미분이 가능하여, 우리는 error를 최소화 하기 위해 gradient descent로 최적화를 수행함
- 위의 과정을 Basic하게 적용할 시, High resolution representation에 한계가 있음을 알게 됨
- 따라서 input인 5차원을 positional encoding을 이용해 고차원의 표현으로 변형해서 이용하였으며 이를 통해 더 high frequency들도 잘 표현함을 알 수 있었음
- 그리고, 계층적(hierarchical)으로 점들을 Sampling하여서 더욱 high frequency 표현을 잘 할 수 있었음
- 본 논문의 Contribution을 정리하면
1. MLP Network를 이용하여 복잡한 geometric에 대해 연속적인 scene들의 예측이 가능하였음
2. 고전적인 volumn rendering technique를 이용하여 미분가능한 렌더링 절차를 따랐으며, 여기에 계층적으로 점들을 Sampling하는 전략을 사용함
3. Positional encoding을 이용하여 5차원의 input 형태를 더 고차원 공간으로 표현하였고, 이를 통해 더 효과적으로 high-frequency scene content를 표현할 수 있었음
Related Works
Neural Radiance Field Scene Representation
- input : x(x,y,z) + d(θ,ϕ) / output : c(r,g,b) + density
- density를 예측하는 것은 x(x,y,z) 위치 좌표만을 이용해서 예측
- c(r,g,b) 예측의 경우, x(x,y,z) 위치좌표와 View Direction(θ,ϕ) 정보를 함께 이용해서 예측함
Volume Rendering with Radiance Fields
- Volume ray casting : 3차원 이미지를 특정 위치에서 보고 2차원으로 어떻게 표현되는지를 보는 것
- 실제 3차원을 보았을 때 보이는 색상은, 가장 겉의 표면의 색깔이 아닌 ! 내가 보고 있는 지점을 쭉 선으로 표현했을 때, 표면을 포함한 그 내부(Particle)의 컬러들과 weighted sum한 색깔임
- 이러한 Weight는 Density에 따라(투명도와 반대개념) 결정됨
- r(t)는 Ray를 의미함, 내 눈 o에서 view direction인 d를 이용해 직선을 구할 수 있음
- 여기서 t는 해당 직선위에 있는, x,y,z 점을 의미함
- 그럼 아래 그림 (a)와 같이 저렇게 선으로 표현할 수 있음
- MLP를 이용하여 rgb,density를 구축하면 C(r)에 따라 한 점의 최종적 2D 상에서 보이는 이미지 컬러를 계산 가능함


- 사실은 위에처럼 연속적으로 모든 particle들의 Density를 보아야 하지만, 실제로 그럴 수 없음
- 따라서 이산적으로 Point들을 뽑아서 해야하며, 아래 식으로 표현 가능함
- 저거가 의미하는 것은 인접한 Sample 사이의 거리를 의미함
- 맨 처음 Sampling의 경우 Stratified Sampling 방법으로 Sampling함


Optimizing a Neural Radiance Field
- 단순 x,y,z 그리고 viewing direction만 사용할 때에 한계가 있었음
- 따라서 Positional encoding과 Hierarchical volume sampling을 이용해 한계를 극복하고 좋은 결과 도출이 가능하였음
Positional Encoding
- x,y,z,θ,ϕ 이것을 단순하게 input으로 사용하였더니 한계가 존재함
- input으로 넣기전에 higher dimensional space로 mapping 시켜줄 때, 더 데이터의 변동에 더 잘 Fit 시킬 수 있음
- to enable our MLP to more easily approximate a higher frequency functions.
- 따라서, 여기서 l은 하이퍼파라미터이며, 기존 1차원이라면 2L차원까지 증폭시켜줌
- 아래 사진과 같이 positioning embedding을 하지 않을 때 Blurry한 경향 있음(High frequency 정보를 제대로 잡지 못한다는 의미를 뜻함)


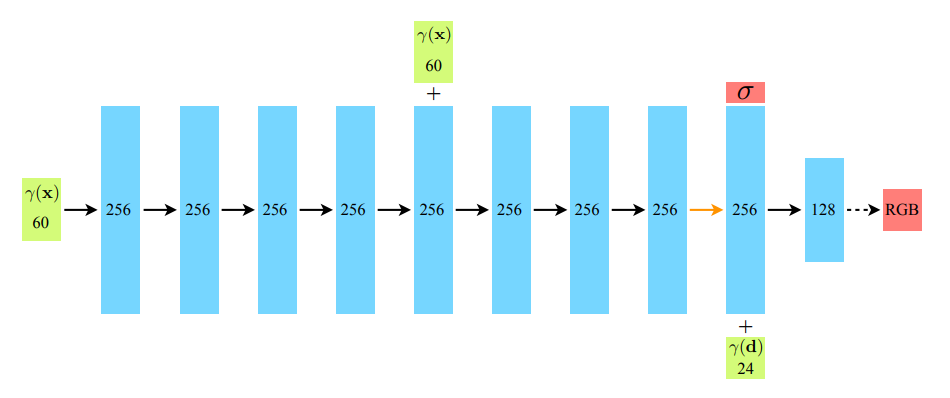
- 본 연구에서는 x,y,z에는 l을 10, viewing direction에는 l을 4로 하였음
- 따라서 x,y,z 위치 좌표에서 Positional embedding 써서 3(xyz 3차원)x10(L)x2 = 60
- viewing direction의 경우 본 논문에서 계속 5D( x,y,z,θ,ϕ ) 라고 강조하였으나, 사실 Viewing Direction을 Cartesian viewtion direction을 사용함 따라서, (θ,ϕ)외에 하나가 더 있어 3차원이며, 그것은 구면 좌표임. 그리고 아마..? 아마.. ? 단순히 1로 적용하여 사용할 것..임 .. ? .. ? ..? >? 그래서 3x4x2 = 24
( https://math.stackexchange.com/questions/4252883/viewing-direction-as-3d-cartesian-unit-vector )
Hierarchival volume sampling
- 각 카메라 ray 마다 N개의 point들을 Sampling 해서 하였는데, 이거가 비효율적임
- 랜더링 하는데에 기여하지 않는, Free space, 가려진 공간 등을 반복적으로 sampling이 됨 따라서 의미없음
- 따라서 계층적으로 Sampling 하여, rendering의 효율성을 높이고자 함
- Single Network를 쓰지 않고, 'coarse','fine' 두개의 네트워크를 사용하며, 이를 optimize함
- 먼저 coarse network의 경우 Stratified sampling을 통해 점 N개를 도출함
- 그리고 그 다음에 coarse network에서 나온 결과를 토대로, Sampling을 다시 진행하여 fine network를 학습시킴
- 아래 식은 Course한 Network를 의미함 아래를 통해 먼저 Course하게 하고, 그 다음 아래 wi^을 구함
- wi^이 의미하는 것은 각 점들의 Weight들의 합을 분모로, 각 점들의 Weight의 비율을 구함으로써 PDF를 구할 수 있음
- PDF란, 확률함수로 예를들어 설명하자면 가우시안분포는 우리가 아는 그 정규분포고 정규분포의 면적의 합은 1임 그 정규분포 산처럼 생긴거를 PDF라고 할 수 있음
- 그래서 이 PDF에서 Fine한 점들을 Sampling 하는 것임 그렇게 되면, Weight가 높은 곳에 있는 Points들이 더 많이 뽑힘


Implementation details
- 본 연구에서는 2D 이미지들과 3D가 페어하게 존재하지 않고, 2D 이미지 셋만 존재하면, 이를 수행가능함
- 맨 처음 이미지세트를 기반으로 카메라의 Ray들을 랜덤으로 Sampling 함
- Loss Function은 아래와 같음 각 Ray들에서 Course Network에서 Nc개를 뽑고 색깔 차이를 보는 거고, 이를 기반으로 Nf개를 추가적으로 뽑아 계층적으로 Sampling 함. Fine Network에서는 Nc+Nf개의 점에서 색깔을 구함
- 따라서 아래 식에 R은 각 배치당 ray들의 집합을 의미함
- Course와 Fine을 모두 Loss Function에 할당함으로써, 가중치 분포로 Sampling 하는 것 또한 더 잘하는 방향으로 갈 수 있음

- 본 논문에서는 각 Batch당 4096 rays, Nc = 64, Nf = 128
- ADAM, learning rate = 5 x 10^-4, 기타 등등. .. ㅎㅎ
- 학습하는데 하루이틀 걸림
Result
- 먼저 synthetic 데이터셋인 Diffuse Synthetic 360(Deep Voxels)이랑 Realitic synthetic 데이터셋(저자가 만듦) 2개를 이용함
- 그리고 Complex한 Realword scene에 대해서도 실험함(Table 1. Real Forward Facing)
- NV를 Real Forward-Facing에서 보지 못한 이유는, NV는 정해진 Boundary 안에서만 Reconstruction만 가능함(Real world 처럼 주변환경 이런게 아니라 한 물체에 대해서만 Reconstruction 가능한 것으로 이해)
- Realworld의 LPIPS가 LLFF 모델에서 더 성능이 우수하다고 나왔지만, 실제 추가자료로 첨부한 동영상을 보면, 본 연구에서 제안한 것이 더 잘 생성한 것을 확인 가능함(Artifact 적고 더 일관성을 달성함)



Discussion
- SRN 방법의 경우 Smoothing 된 경향이 존재함 이러한 표현을 하는 이유는 카메라 ray 당 하나의 Depth와 Color를 선택하기 때문에 그런 것이다..?
- NV의 경우, 128^3 그리드를 사용하는데, 이는 고해상도의 미세한 부분을 캡처하기 위해 그 부분만 더 세부적으로 나눌 수가 없다는 한계가 있음
- LLFF는 서로 다른 input niew들간의 상이한 부분이 64 pixel을 넘지 않도록(?) Sampling 전략을 세웠기 때문에, 각 View들이 최대 400~500 pixel 정도 다를 때, 올바르게 생성하지 못하는 단점이 있음 따라서, 혼란스럽게 보이는 부분이 존재함
- 시간과 공간이 tradeoff 관계임
- LLFF 빼고, 최소 12시간 이상의 학습시간이 필요함. 하지만, LLFF는 단 10분이면 input 데이터의 수가 적을 때 가능함
- 하지만 LLFF는 3D Voxel grid로부터 하기 때문에, 엄청난 저장공간이 필요함
- LLFF에서 15GB 필요한 것이 본 논문에서는 5MB만 필요함 약 3000배정도 차이가 남
Ablation Study
- d이 결과는 Realistic Synthetic 360(저자들이 만든 데이터셋)으로 평가한 것임
- PE(Positional Embedding), VD(Viewing Direction), H(Hierarchical smapling)을 의미함
- 5번줄과 6번줄은 입력 이미지의 수를 감소해서 사용한 것을 의미하는데, NC, SRN, LLFF에 100개의 이미지를 제공하는 거랑, 본 논문 방법에서 25개의 이미지를 제공하는 거랑 비교했을 때, 본 논문이 더 성능이 좋음
- 7번과 8번은 Positional Embedding시에 L을 몇을 사용하냐(xyz에서 최종적으로 10 채택)에 따라 비교한 것임
